一、结论先行:零风险、可普适、可落地
在全球化业务背景下,跨境数据流动与合规监管正成为企业合规治理的核心议题。日志,作为支撑业务连续性、技术运维、风险审计的基础设施性资产,其重要性毋庸置疑。如何在保障合规要求的同时,仍然高效地利用日志进行故障排查、性能优化与业务分析,已成为企业必须正视的挑战。
传统做法常常依赖:
严格的地域限制:要求相关人员必须身处境内查看本地日志(如仅限美国团队查看美国用户日志)。
正则或NLP手段:在日志流中逐条匹配、标注、脱敏。
然而,这些方式要么影响效率、无法跨区域协作,要么存在漏检与误杀的问题。通过将日志文本建模成Token长序列,我们基于日志模式识别与变量抽取,能够在 不泄露任何用户敏感数据的前提下,保证 跨境日志可共享、可分析、可审计。
这一方案的价值可总结为:
零风险:仅传递“模式”而非“变量”,天然杜绝敏感信息泄漏。
普适性:不依赖业务语义、语言环境,适用于任何系统日志。
可落地:结合 Drain3 的模式识别能力,已具备成熟的工具链与流程。
二、为什么不选择传统方式
正则匹配PII的不足
需要对所有可能字段提前定义规则,维护成本极高;
极易出现漏检(如手机号拼写变形)或误判(如业务ID与手机号格式相似)。
NLP方法(如微软 Presidio)的局限
模型依赖语言与上下文,对多语种、多域日志不稳定;
需要高算力实时推理,无法在高吞吐日志场景中普遍部署;
对合规场景而言,“猜测某条数据是否是PII”并不等于“百分百保证敏感信息不会泄漏”。
与其他方法的对比
补充说明:
NLP 方法在本方案中可作为 辅助:在模式发现后,对变量进行自动归类和审批,以提升管理自动化程度。
相比之下,基于 日志模式识别 + 变量泛化 的方法,直接从根源解决了“变量是否敏感”的问题,绕过了正则和NLP的固有缺陷。
三、技术核心:日志的模式化与变量隔离
通常情况下业务代码会通过两种方式输出日志
// 1. 静态日志
logger.CtxInfo(ctx, "this is a static log")
// >> this is a static log
// 2. 动态日志(格式化日志)
logger.CtxInfof(ctx, "User %d from %s clicked Ad %d", 12345, "US", 67890)
// >> User 12345 from US clicked Ad 67890其中 12345 与 67890 是动态变量,而句式是固定的模式User <:*:> from US clicked Ad <:*:> 。由此我们可以看到日志通常是高度模式化的,并且由静态部分与动态部分组成
静态部分:连续的单词组成的固定的句式、模板。
动态部分:变量(往往承载PII、业务标识等)。
而通过隐藏动态部分将日志展示为这样固定的模式就能实现数据合规口径下的“匿名化”
将日志切分为词元(token)长序列;
通过“增加、删除、替换”词元的最少操作次数(编辑距离)来衡量句子相似度;
相似度高的日志归为同一簇,差异部分即变量;
最终得到 压缩前缀树(compact prefix tree),可对所有日志自动聚类与模式化。
业界中已存在成熟算法:Drain3(https://github.com/logpai/Drain3),已验证可在大规模流式日志场景下稳定运行。
四、合规运营流程
完整流程如下:
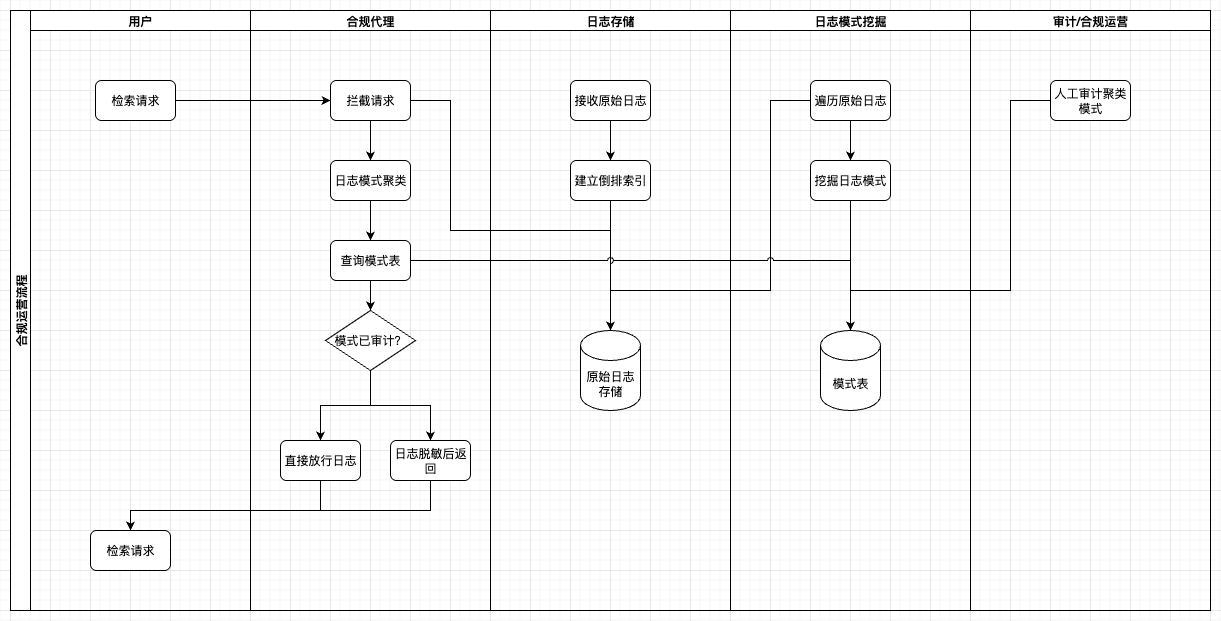
定期挖掘
使用 Drain3 对日志流进行聚类,得到稳定的模式集合。
生成模式表
将模式与其变量占位符存入“模式表”。
示例:
Pattern: "User <:*:> from <:*:> clicked Ad <:*:>" Variables: [user_id, country, ad_id]
推送模型(前缀树)到日志代理
模式表以压缩前缀树形式下发到日志代理(OpenSearch Dashboard - Compliance Proxy -> OpenSearch)。
日志模式识别与脱敏
日志采集时先匹配模式;
若匹配成功 → 仅输出模式(含占位符),丢弃具体变量;
若未匹配成功 → 进入临时隔离。
人工可审计放行
新模式需经过合规审核:确认变量中不含敏感信息,或确认敏感字段已匿名化。
审核通过后更新模式表并重新下发。
通过该机制,任何流出跨境的日志均已“变量屏蔽”,而原始变量仅保留在本地合规边界内。
五、价值
减少人工正则维护成本,日志处理统一化。
提升跨境协作效率,降低运维支持时差与地域限制。
保证合规风险为零,满足跨境运营法律要求。
六、结语
跨境数据合规不是单一的技术问题,而是产研运售法各角色都必须共同遵循的底线要求。本方案通过模式化日志与变量隔离,从技术层面彻底解决跨境日志共享与合规的矛盾,既实现了零风险,又兼顾了业务与运维的实际需求。
相比正则或NLP手段,这一方案不仅更稳健、更普适,也更容易在大规模生产环境中落地。我们相信,这将成为跨境系统中日志合规治理的 最佳实践。